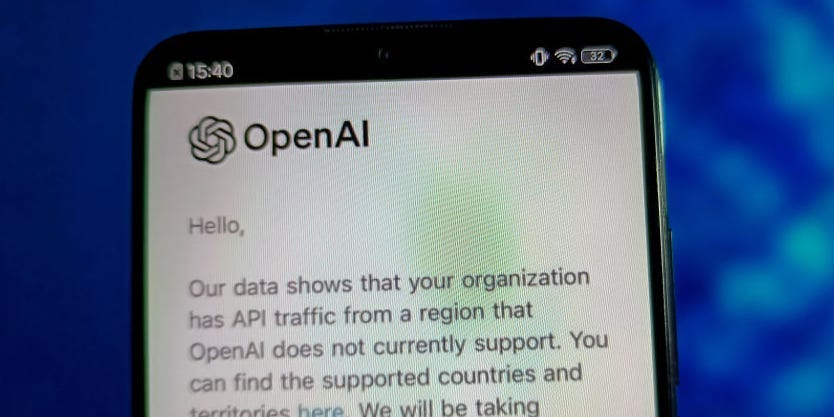
OpenAI uses any and all publicly available data to train ChatGPT, including books and articles from the internet. Now, those who own them want to be paid for their work.
Training data is an essential part of creating the AI models that are taking over the tech world. Leading tech companies like Google, Meta, OpenAI, Anthropic, and Microsoft are all scrambling to find new sources of data. Meta at one point even considered buying Simon & Schuster, one of the world’s biggest publishing houses.
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased









{kind=link}